1.集群 cluster
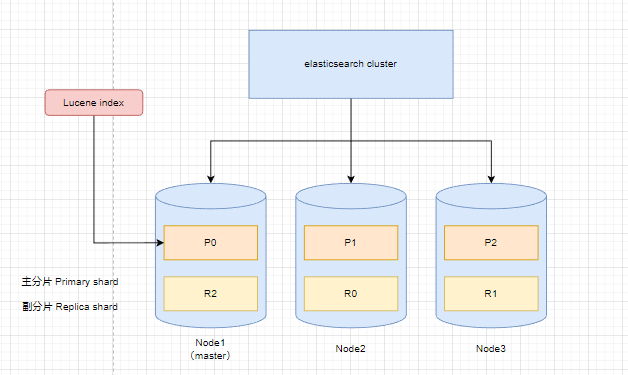
集群部署拓扑图
副分片的数量可以设置的,一个Primary shard可以对应多个Replica shard将所有数据主分片分到多个节点node中,将副分片保存在不同的节点中 (主要避免某个节点不可用时,其他节点可以提供数据使用或恢复)
集群状态颜色
- 绿色
- 黄色
- 红色
单点故障转移
当只有一个节点的时候,副本RS是不会生效的,表示节点宕机时候,数据还是不可用,不会冗余数据。容错率是0%。
当只有两个节点时,数据会会有主分片和副分片,每个node上都有完整的数据。容错率是50%。
当有多个节点时候,为了分散负载堆分片重新分配。(CPU,RAM,I/O)等资源被更少数据共享。
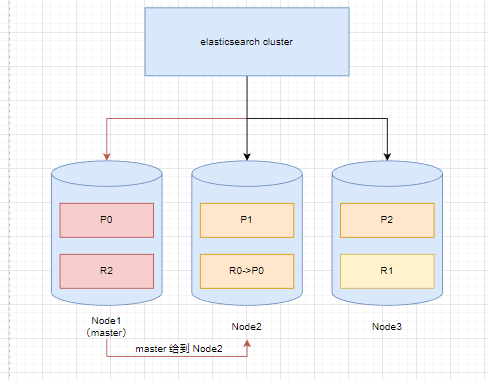
集群故障转移
集群故障转移
集群中一个节点故障,故障节点
primary shard的副本Replica shard会主动升级为primary shard继续提供服务。然而如图所示,只剩下6 of 9节点使用,集群状态为yellow。
路由计算 & 分片控制
分片逻辑: SHARD = HASH(routing)%number_of_primary_shards
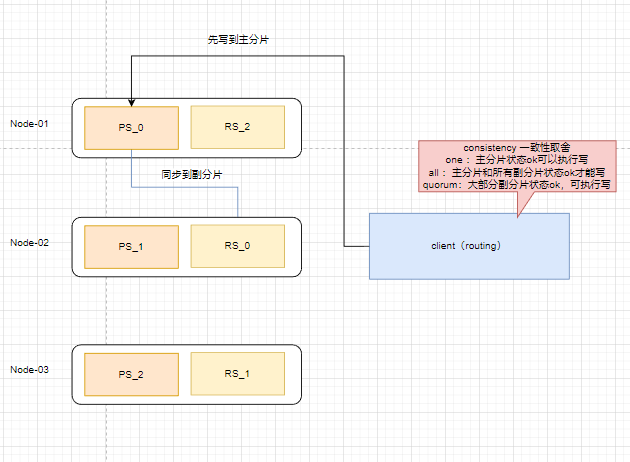
数据写流程
请求会走到协调节点,协调节点可以是集群中任意节点。
客户端写请求
1.客户端协写请求(协调节点)
2.协调节点到指定分片节点
3.主节点保存数据
4.主节点发送数据到副本(可以设置副本同步时间)
5.副本保存后反馈
6.主分片反馈
7.客户端收到,写请求完成
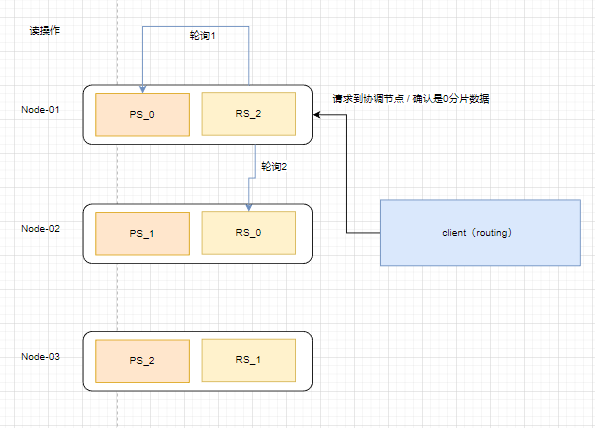
数据读流程
协调节点是任意的,节点分为数据节点,协调节点,master节点
客户端读操作
1.协调节点获取请求
2.计算DSL语句,找到主分片,副分片所在的节点
3.根据轮询策略,请求转发到其他节点上
4.协调节点获取到查询文档后,返回给客户端
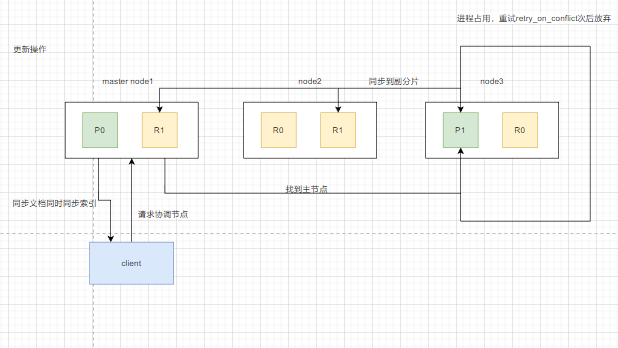
数据更新流程
更新数据
1.客户端调用协调节点
2.协调节点找到数据主分片,同步数据和索引
3.从主分片读取_source,若主分片被其他进程占用,会重试至放弃。
4.主分片同步完,给所有副分片发送文档同步和索引同步
5.所有副分片返回成功,主分片返回成功给协调节点,最终返回给客户端
倒排索引
Elasticsearch使用倒排索引的结构,它适用于快速的全文搜索。
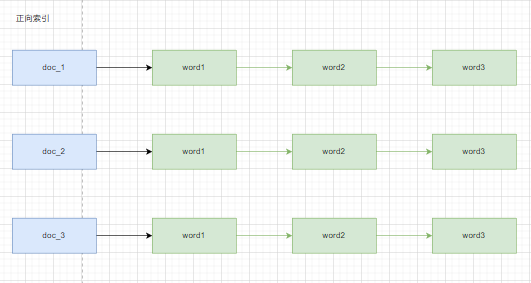
正向索引
先介绍什么是正向索引
搜索引擎会把文档对应文件的一个ID,根据ID搜索到对应的文档和字段。
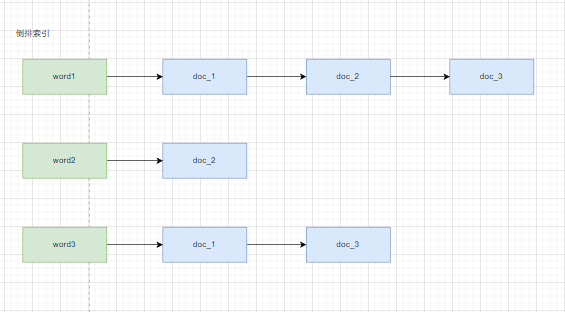
倒排索引
倒排索引就是根据对应的关键字,找到对应的文档
建立关键字与所有关联的文档内容,id等等信息
难点:todo
微信
 支付宝
支付宝

...
...
This is copyright.