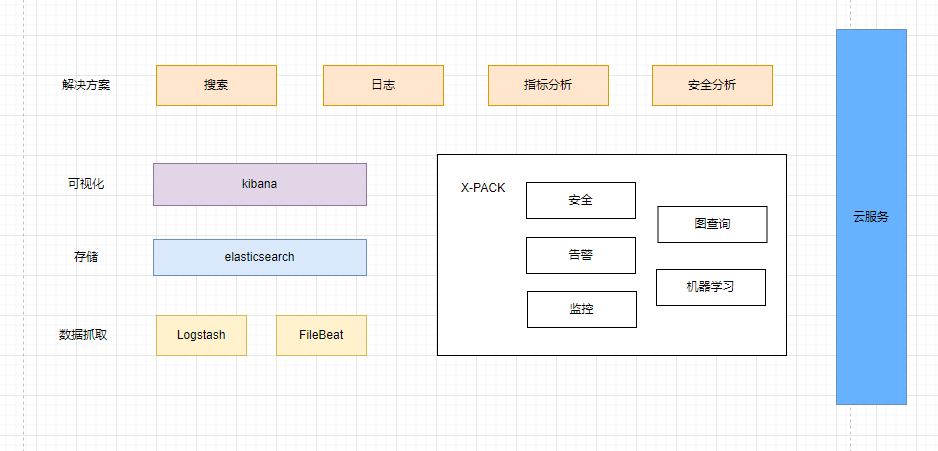
浅显概括一下es的能力:分词能力,倒排索引,聚合计算能力。
能力示意图
实际应用场景
稍微了解一下elasticsearch生态
1.实时日志分析
主要运用场景:用户行为的业务日志(埋点),运营日志(系统的慢性能的接口)等等
通常这种场景使用elk/efk完成:
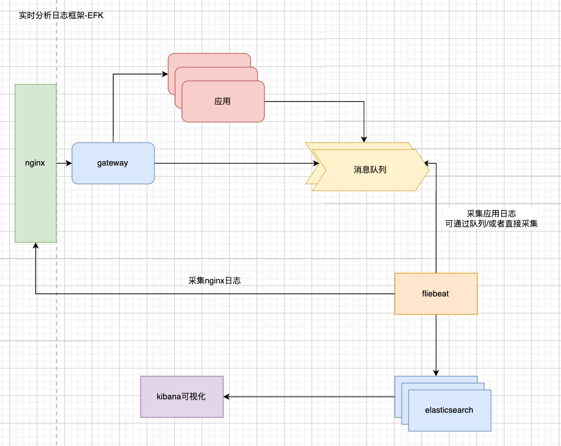
扩容:
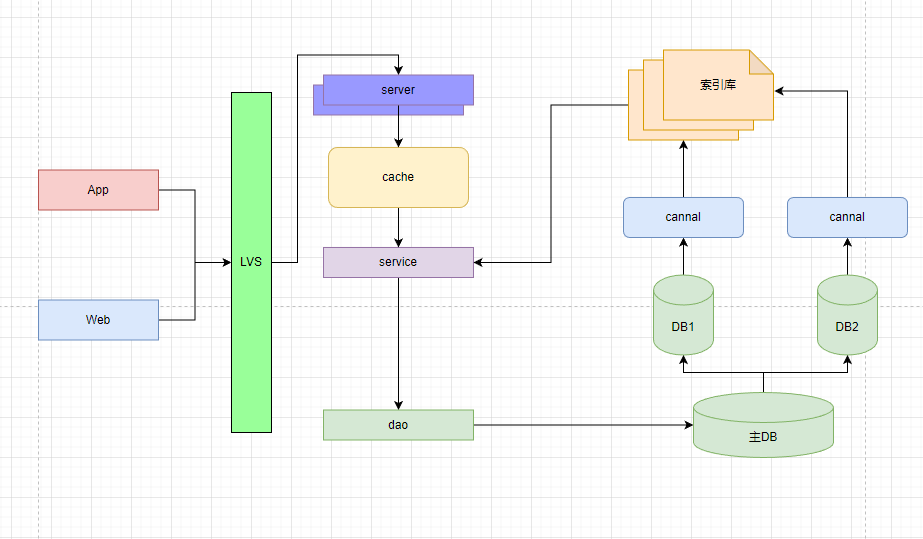
2.搜索服务
微服务小程序内容索引架构,可以基于不同业务将数据拆分为多个子库做业务隔离。
适用业务
例如:feed流
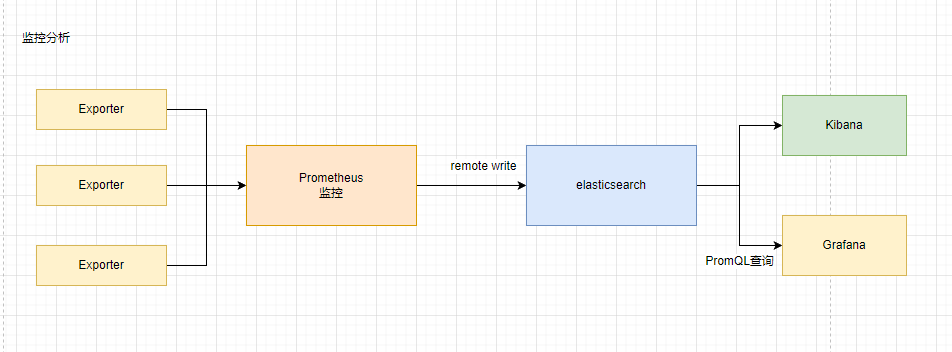
3.时序分析
TimeStream优化Elasticsearch在存储指标数据方面的DSL查询复杂且慢以及存储成本过高等问题
1 | PUT _time_stream/test_stream |
TimeStream+Es+Prometheus+Grafana
es集群优化方案
1.主要的优化项
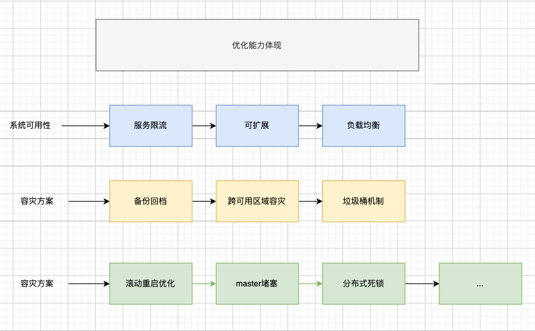
优化方案
限流方案:
- 内部服务调用权限,只有认证的服务才能进行调度。
- 使用队列:优化队列优先级
- 内存优化使用:全链路 + 精准匹配
- 多租户: CVM/Cgroups
成本优化方案:
硬件成本
- 冷热分离:使用混合存储平衡成本,性能
- Rollup:预计算换取存储,性能
- 备份归档:使用廉价的存储系统备份
- 存储裁剪,生命周期管理等等
内存成本
- LRU Cache:提升内存利用率
- Off Heap:降低堆内存,提高节点规格
方案实践
es6.x开始推出Rollup。
Rollup 类似于大数据场景下的 Cube、物化视图,它的核心思想是通过预计算提前生成统计信息,释放掉原始粒度数据,从而降低存储成本、提高查询性能,通常会有数据级的收益。
// TODO
索引汇总作业
https://www.modb.pro/db/444747
...
...
00:00
00:00
This is copyright.