零.共识
查询组件单线程,链接多路复用,有事务提交,但不能回滚。
一.redis部署架构
1.单机架构
忽略吧 单机架构有相当多问题
- 1.单点问题
- 2.多路复用
- 3.
2.哨兵架构
在部署redis的同时也需要部署哨兵,哨兵主要功能分为:
- 监控redis主从节点的运行状况
- 当master节点挂了之后,选出master
部署拓扑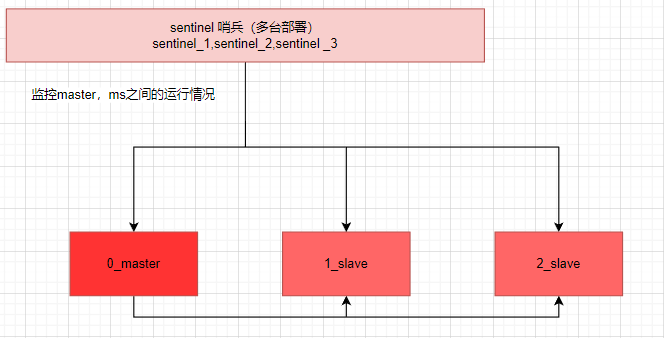
master节点配置1
2
3
4
5
6
7
8
9
10
11
12
13
14### REDIS MASYER
port 6379
daemonize no
#logfile "6379.log"
dir /redis-4.0.0/data
dbfilename dump-6379.rdb
rdbcompression yes
rdbchecksum yes
save 10 2
appendonly yes
appendfsync always
appendfilename appendonly-6379.aof
bind 127.0.0.1
databases 16
slave节点配置1
2
3
4
5
6### REDIS SLAVE
port 6380
daemonize no
#logfile "6380.log"
dir /redis-4.0.0/data
slaveof 127.0.0.1 6379
sentinel哨兵节点配置1
2
3
4
5
6
7
8
9
10
11### SENTINEL
port 26379
dir /redis-4.0.0/data
# 监控 主 连接字符串 哨兵判挂标准(几个哨兵认定他挂了,就判定为主挂了,通常为哨兵数量的一半加一)
sentinel monitor mymaster 127.0.0.1 6379 2
# 无响应时间,为挂掉
sentinel down-after-milliseconds mymaster 30000
# 主挂了之后,新的主上任同步数据的路线数量,数值越小,对服务器压力越小
sentinel parallel-syncs mymaster 1 #
# 新主同步数据时,多长时间同步完算有效 (默认 180s)
sentinel failover-timeout mymaster 180000
自动故障转移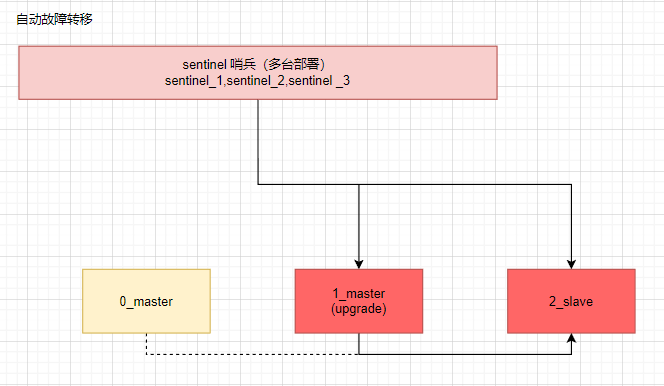
如何选择新的redis主节点呢?
当master节点跟哨兵过半失联的时候会发生重新选举:
1.优先级排序,可以根据配置文件的
replicapriority n来判断优先级,n越小越优先。2.复制数量,如果优先级相同,复制偏移量最大的选主(表示复制原master数据最多)
3.进程id,如果复制数量也相同,就选择进程id最小的那个
数据流动
// TODO
spring配置
// TODO
集群架构 Cluster
Redis Cluster是服务器sharding技术,redis3.0开始支持。
数据会根据slot分配给多个master,对应的master和slave的数据时相同的;
当master宕机时候,对应的slave会顶替master位置继续提供服务。
gossip是提供给集群内所有节点的一个数据最终一致性方案,但会根据slot获取对应的数据。
每个master节点都根据slot分配不同的数据,但由于增加节点/裁撤等等变更会导致slot之间数据迁移,通过gossip协议同步。
gossip协议是一个随机通信,可以理解为“传染病”,在传播信息同时会有延迟(缺点)
部署拓扑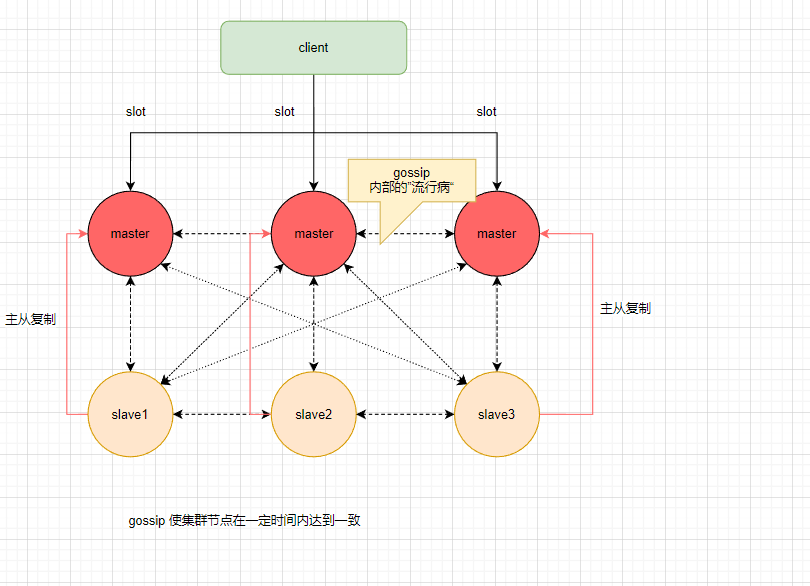
gossip协议适用场景:新增节点/slot迁移/节点宕机/slave选举为master(slave可以使多个master的从节点)
gossip 协议包含多种消息,包括 ping,pong,meet,fail 等等。
spring配置
redission链接cluster1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21spring:
redis:
# host: 127.0.0.1
# port: 6379
cluster:
nodes: 127.0.0.1:7001,127.0.0.1:7002,127.0.0.1:7003,127.0.0.1:7004,127.0.0.1:7005,127.0.0.1:7006
password: 123456
## Redis数据库索引(默认为0)
database: 1
lettuce:
pool:
## 连接池最大连接数(使用负值表示没有限制)
max-active: 100
## 连接池最大阻塞等待时间(使用负值表示没有限制)
max-wait: 100000
## 连接池中的最大空闲连接
max-idle: 10
## 连接池中的最小空闲连接
min-idle: 0
## 连接超时时间(毫秒)
timeout: 30000
POM依赖1
2
3
4
5<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.12.5</version>
</dependency>
SPRIING REDIS CONFIG1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
public class RedissonConfig {
("${spring.redis.cluster.nodes}")
private List<String> nodes;
("${spring.redis.password}")
private String password;
("${spring.redis.database}")
private Integer database;
public RedissonClient clusterRedisClient() {
Config config = new Config();
ClusterServersConfig clusterServersConfig = config.useClusterServers();
if (!StringUtils.isBlank(password)) {
clusterServersConfig.setPassword(password);
}
// 集群状态扫描间隔时间,单位是毫秒
clusterServersConfig.setScanInterval(2000);
for (String node : nodes) {
String url = "redis://" + node;
clusterServersConfig.addNodeAddress(url);
}
RedissonClient redissonClient = Redisson.create(config);
return redissonClient;
}
}
codis框架图
codis 包含 codis-proxy,codis-redis-group,codis-redis 3个组件
二.适用场景
- 缓存
- 秒杀
- 支付配置
- 热点数据
- 配置信息
- zset 实现
- redis-hash 两种实现
三.实际问题及其解决方案
1. 大key原因及解决方案,为何大key会引起性能问题
1.1 影响性能的主要原因
1.1.1 占用内存增大:相比于正常的Key,读取大key需要的内存会有所增大,
如果像是value中的list不断变大,可能会造成OOM(内存溢出),
还有一种就是达到redis设置的最大内存maxmemory值会造成写阻塞或者部分重要的Key被redis的淘汰策略给删除了。
- hash性能问题主要体现在遍历链表,当hash量很大时会存在hash冲突,然后redis要做大量的rehash。
1.1.2 网络阻塞延迟变大:在读取大key的时候,由于读取的内容较多,占用较大的带宽,造成网络带宽的阻塞,也会影响其他的应用,导致网络阻塞延迟变大。
- 主从模式,大key会使内存使用不均匀。
- 若key达到M,访问为1000,每秒1000M流量,千兆网卡顶不住。
- 排查是否有bigkeys
1
2排查大对象
redis-cli -h {ip} -p {port} bigkeys
1.1.3 IO阻塞延迟增大:主流程为单线程,读写时串行的,多个请求过来时,可能因为单个BigKey的原因可能造成IO阻塞延迟。
- swap 如果一个 Redis 实例的内存使用率超过可用最大内存(used_memory > 可用最大内存),那么操作系统开始进行内存和 swap 空间交换,把内存中旧的或不再使用的内容写入硬盘上(硬盘上的这块空间叫 Swap 分区),以便腾出新的物理内存给新页使用。
- fork 子进程,在 RDB 生成和 AOF 重写时,会 fork 一个子进程完成持久化工作,fork持久化与数据集有关
- AOF 刷盘阻塞,开启 AOF,文件刷盘一般每秒一次,硬盘压力过大时,fsync 需要等待写入完成。 查看 redis 日志或 info persistence 统计中的 aof_delayed_fsync 指标。
1.1.4 BigKey迁移困难:这个问题是出现在Redis集群中,实际上是通过migrate命令来完成的,migrate实际上是通过dump + restore + del三个命令组合成原子命令完成,如果是bigkey,可能会使迁移失败,而且较慢的migrate会阻塞Redis。1
2
3
4
5
6## MIGRATE [HOST] [PORT] [DB] [TIMEOUT]
MIGRATE 127.0.0.1 7777 key 0 1000
## MIGRATE 相当于 dump del restore
dump 源实例
del 源实例
restore 目标实例
2. 设计方案:一个接口查询100key提高性能
2.1 管道 pipeline 替换普通的set-key-value
使用pipeline可以减少多次命令执行的网络等待时间,提高多个key操作的相应速率。1
2
3
4
5
6
7
8
9
10
11
12
13public class PipelineExample {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
// 获取 Pipeline 对象
Pipeline pipe = jedis.pipelined();
// 设置多个 Redis 命令
for (int i = 0; i < 100; i++) {
pipe.set("key" + i, "val" + i);
}
// 执行命令并返回结果
List<Object> res = pipe.syncAndReturnAll();
}
}
2.2 内部缓存(不适合数据量大的场景)
将小量且不变的数据存储在gavua-cache中,不使用网络访问redis,去除不使用建立网络链接的时间,提高速度。
3. redis集群引发多个key不落在同一个槽位(slot)问题
3.1 引发原因
redis在单节点情况下槽位是属于一个片区的,同一个key在hash运算下一定会分配到一个一个节点上。
然而在集群模式中,槽位负载均衡到不同的节点上,通过hash计算的key值具体落槽点在不同节点上。
同时引起另外的问题,在集群模式中,一个请求多给key进行操作限制在一个slot中,不能跨槽执行。
lua脚本对多个key进行操作的时候,key在hash后落在多个slot。会引发“CROSSSLOT Keys in request don‘t hash to the same slot”
3.2 解决方案
主要原因:
- 业务操作多个key,且key不在同一个节点上
解决: - 根据业务不同的key,分别在不同的业务中执行
- 可以根据唯一的key将业务属性放在一个map中
槽位(slot): Redis集群通过分片的方式来保存数据库中的键值对,集群的整个数据库被分为16384个槽,数据库中的每个键都属于这16384个槽的其中一个,集群中的每个节点可以处理0个或最多16384个。
四.压测方案及容灾方案
容灾方案
当设计一个中间间架构的时候把其独立起来,上游服务仅是调用,使中间件的扩展与维护对于服务来说是无感的,类似于laas服务。
然而设计一个这样的中间间架构需要多层的服务。
接入层:LVS/DNS
- 基于NAT的LVS模式负载均衡
- 基于TUN的LVS负载均衡
- 基于DR的LVS负载均衡
应用层
可拆分为局部状态
- 分号段分区,降低影响面
- 备份部署,直接快速切换
- 可实施有损服务等应用
优点:取决业务柔性及部署合理性,开发时间投入少。
缺点:部署不合理会导致灾难时损失倍增。
数据层
一致性强应用
优点;保障上层数据完整
缺点:技术实现复杂,然而使用的机器资源很大
redis持久化的两种方式:
- RDB 指定时间间隔数据快照储存。
- AOF 记录服务器写操作。服务器重启时重新执行。(redis支持后台重写AOF,减少AOF文件大小)
RDB持久化
镜像全量持久化
1 | ## 主线程执行,会阻塞 |
1 | ## 子程执行,redis默认配置 |
fork 使子进程同步父进程的共享数据块,当一个子进程fork时,别的子进程访问时会直接返回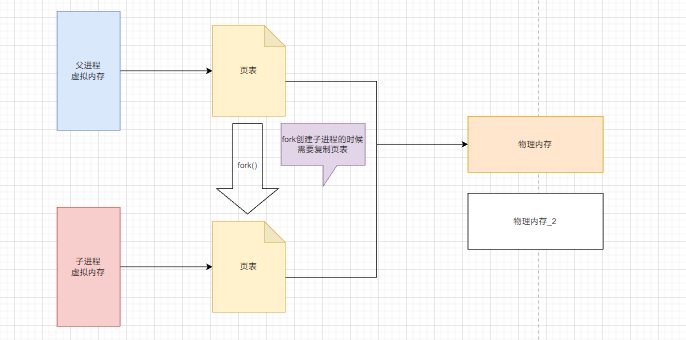
COW(copy on write)操作,子进程创建之后,父子进程共享数据段,父进程继续提供读写服务,将子进程脏写的数据清理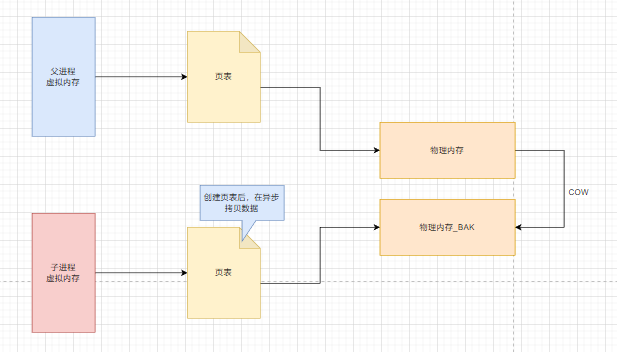
- 执行 bgsave 命令,Redis 父进程判断当前是否存在正在执行的子进 程,如 RDB/AOF 子进程,如果存在bgsave命令直接返回。
- 父进程执行 fork 操作创建子进程,fork 操作过程中父进程会阻塞,通 过 info stats 命令查看 latest_fork_usec 选项,可以获取最近一个 fork 操作的耗 时,单位为微秒。
- 父进程fork完成后,bgsave 命令返回 “Background saving started” 信息 并不再阻塞父进程,可以继续响应其他命令。
- 子进程创建 RDB 文件,根据父进程内存生成临时快照文件,完成后 对原有文件进行原子替换。执行lastsave命令可以获取最后一次生成 RDB 的 时间,对应 info 统计的 rdb_last_save_time 选项。
- 进程发送信号给父进程表示完成,父进程更新统计信息,具体见 info Persistence下的 rdb_* 相关选项。
AOF持久化
增量持久化
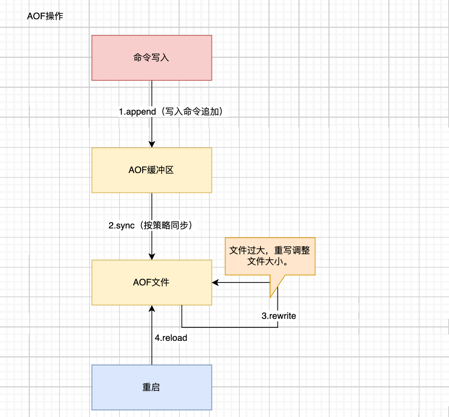
- 所有的写入命令会追加到aof_buf(缓冲区)中。
- AOF缓冲区根据对应的策略向硬盘做同步操作。
- 随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩的目的。
- 当Redis服务器重启时,可以加载AOF文件进行数据恢复。
容灾方案拓扑
整体的数据一致性架构,可见数据层要做实时备份需要大量的资源。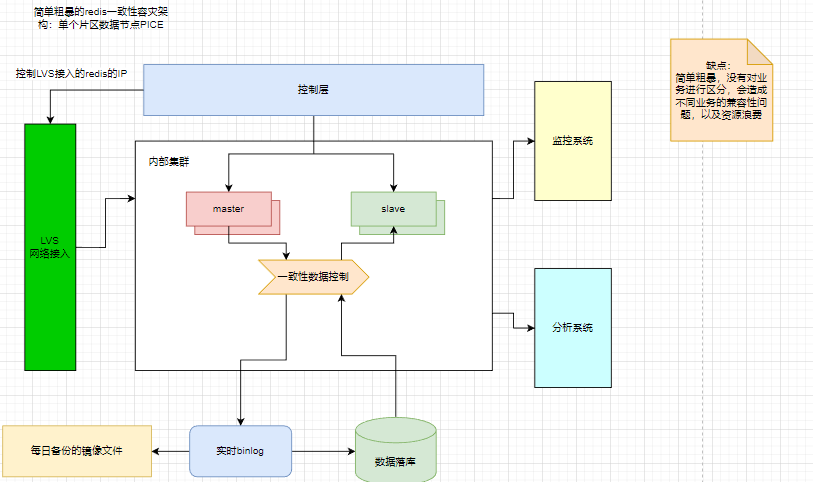
redis中间件集群架构
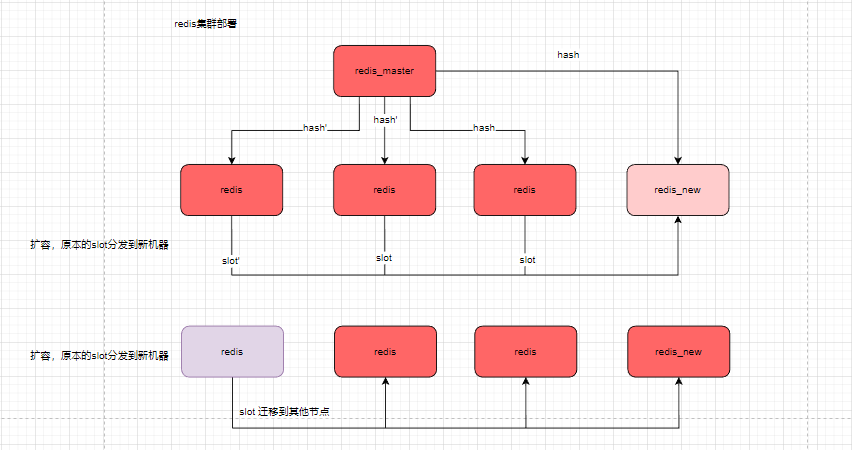
主要场景:
扩容/缩容: 集群模式部署
切换
数据迁移/快速迁移数据/减少迁移时影响面
压测方案
1.目标
2.资源选择,部署方案
3.实际压测结果
容灾方案
集群架构部署及容灾
哨兵结构容灾方案
五.数据迁移与备份
// todo
六.版本特性
// todo
微信
 支付宝
支付宝

...
...
This is copyright.